A clustering illusion megnevezésű kognitív torzítás azt eredményezi, hogy olyan összefüggések alapján hozunk döntést, melyek a valóságban nem léteznek. Sajnos a tőzsdei kereskedés, a pénzügyek, a befektetések területe kedvez ennek a hibának, tekintettel arra, hogy a befektetők, a tőzsdei kereskedők a jövőbeni változásokat próbálják előrejelezni. Témáink:
- Mit jelent a clustering illusion?
- Clustering illusion oka a pénzügyekben, tőzsdén
- Clustering illusion példa a tőzsdén
- Clustering illusion a befektetések területén
- Clustering illusion a befektetési alapok kiválasztása során
- Lineáris regresszión alapuló kutatások és a clustering illusion
- Hogyan kerülhető el a clustering illusion?
- A bangladesi vajtermelés és a tőzsdei előrejelzés
Mit jelent a clustering illusion?
A clustering illusion megnevezésű kognitív torzítás azt jelenti, hogy az emberek hajlamosak összefüggéseket találni, melyek a valóságban nem léteznek, és ezekre az összefüggésekre alapozva hibás döntéseket hoznak. Gyakori, hogy két adat, két tényező között összefüggést, korrelációt vélünk felfedezni, de a valóságban a két esemény nem korrelál. A hétköznapi életben is számos formában megnyilvánul a clustering illusion, például egyesek azért lottóznak, mert azt hiszik, vannak bizonyos számok, melyekkel nagyobb esélyünk van a főnyereményre. Ugyanígy a szerencsejátékosok tévedése is egyik megnyilvánulása a clustering illusion hibájának. Például azt gondoljuk, hogy a rulett játékban, ha egymás után többször esett feketére a golyó, akkor nagyobb a valószínűsége a következő körben a pirosnak. Ez az összefüggés a valóságban nem létezik. Ugyanakkor látni kell azt, hogy a pénzügyek, a befektetés, a tőzsde területe kedvez igazán a clustering illusion hibájának, egész egyszerűen azért, mert ebben az esetben a jövőbeni események valószínűségeit próbáljuk meg előrejelezni. A clustering illusion kognitív torzításának kutatása Thomas Gilovich, Robert Vallone és Amos Tversky munkáihoz köthetők, így részletesen a hivatkozott kutatásokban találjuk meg a probléma leírását.
A clustering illusion lényege tehát, hogy jellemzően alacsony esetszámú eseményen megfigyelünk egy összefüggést, mely a valóságban csak a véletlennek köszönhető. Ugyanakkor mi ezt az összefüggést alkalmazzuk a döntéseink során, holott ha nagyobb esetszámon vizsgáltuk volna meg az összefüggést, akkor kiderült volna, hogy nem létezik.
Clustering illusion példa a tőzsdén
Kitűnő példát mutat be a clustering illusionnal kapcsolatban Burton Malkiel profeszor a random walk (bolyongás) elmélet megalkotója. A random walk elmélet szerint, mely a hatékony piacok elméletének gyengébb formája, a részvényárak változásai függetlenek egymástól, azaz a múltbeli árváltozásokból nem következtethető ki a jövő. Ugyanakkor, ha az alábbi grafikont megmutatjuk egy technikai elemzésben jártas kereskedőnek, elemzőnek, akkor azonnal trendeket vél felfedezni a grafikonon.
forrás: Random_Walk_Hypothesis
A fenti grafikonon látható árfolyammozgás véletlenszerűen generált adatokból lett kialakítva. Képzeljük el azt az esetet, hogy egy részvény kezdeti ára 50 dollár, a nap végi záróárat pedig érmefeldobással döntjük el. Ha fejet dobunk, akkor a záróár 0,5 dollárral magasabb, ha írást dobunk, akkor a záróár 0,5 dollárral alacsonyabb lesz. Gyakorlatilag minden nap 50-50% az esélye, hogy a részvény ára emelkedni, vagy csökkenni fog, azaz véletlenszerűen alakul. Ugyanakkor a fej-írás eloszlása nem egyenletes lesz, ezért a grafikonon trendeket fogunk tapasztalni. Az alábbi képen a fenti módszerrel létrehozott részvényárfolyam látható, mely teljesen összevethető egy átlagos részvény árfolyammozgásával.
Clustering illusion a befektetések területén
A befektetési alapokba történő befektetés során a befektetők rendszeresen elkövetik a clustering illusion hibáját. Egész egyszerűen azért, mert legtöbbször olyan tényezők alapján döntenek az alapkezelők között, melyek nem állnak összefüggésben az alap várható jövőbeni hozamával. Jó példa erre, hogy azokat az alapokat vásároljuk, melyeknek a legnagyobb volt a hozama az elmúlt 3-5 évben, és egész egyszerűen arra számítunk, hogy a jövőbeni is ilyen magas hozam lesz, kivetítjük a magas hozamot. Holott kutatások arra mutattak rá, hogy a fentiekkel ellentétes hatásra számíthatunk. Ez az ún. long-term reversal hatás, azaz a 3-5 éves távon jó teljesítmény hozó részvények/tőzsdék alulteljesítenek a következő 3-5 éves távon.
Szintén jellemző a befektetőkre, hogy a befektetési alapokat rangsorba állítják, és a legjobb teljesítményű alapba fektetik a pénzüket, arra az összefüggésre alapozva, hogy ha egy alapkezelő sikeres volt a múltban, akkor a jövőben is sikeres lesz. Az alábbi táblázat összegzi a U.S Persistence Scorecard adatai alapján az elmúlt 5 évre, több száz befektetési alapra kiterjedő vizsgálat eredményét. A táblázat felső soraiban azokat a befektetési alapokat láthatod, melyek öt évvel ezelőtt a legsikeresebb alapok körébe tartoztak (Top Quartile alatt különböző lebontásban). Ezek az alapok az összes befektetési alapnak a legkiválóbb 25 százalékát adták. A táblázat következő oszlopaiban azt láthatod, hogy ezen alapoknak mekkora hányada tudott a következő években is a legsikeresebb alapok körében maradni. Jól látható a táblázatból, hogy az összes befektetési alapon vizsgálva a következő évben 48,58%, majd a 33,21%, végül 1,71% és 0% tudott a sikeres alapok körében maradni. Eszerint tehát öt év múlva egyetlen alapot sem találtunk legsikeresebbek között. Az eredményeken az sem változtat lényegesen, ha a sikeres alapok kiválasztásakor nem a legsikeresebb 25 százalékra, hanem a legsikeresebb 50 százalékra, azaz az összes alap felére vonatkoztatjuk. Ebben az esetben öt év múlva az összes múltbeli sikeres alap 2,66 százaléka tudott a legsikeresebb 50 százalék körébe tartozni.
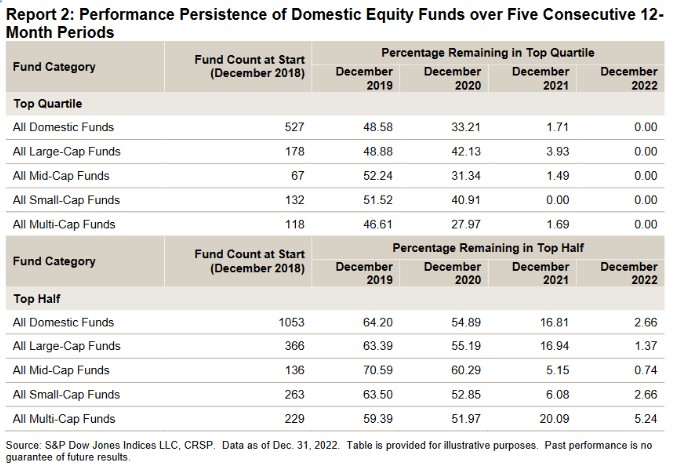
Hogyan kerülhető el a clustering illusion?
Sajnos még a legmagasabb szakmai színvonalat képviselő kutatásokban is találunk olyan eseteket, amikor a szerzők elkövetik clustering illusion hibáját. Ezek az esetek azonban abban térnek el a fentiektől, hogy nagy esetszámon is megfigyelhető összefüggésekről van szó, és legtöbbször a lineáris regresszió hibája miatt alakul ki. Egész egyszerűen arról van szó, hogy egyes összefüggések nem feltétlenül lineárisak, viszont az emberek nagyrészt lineárisan tudnak gondolkodni. Jó példa erre egy 2008-as kutatás, mely az amerikai nemzeti egészségügyi és táplálkozási vizsgálati program alapján kiszámolta, hogy 2048-ra az összes amerikai állampolgár túlsúlyos lesz. Ha ugyanis megvizsgáljuk az 1970-es éveket, akkor az amerikaiak 50% volt elhízott, a 90-es években már a 60 százalékuk, és 2018-ban már a 75 százalékuk. Ha ezt az összefüggést lineáris regresszióval vizsgáljuk, akkor az egyenest meghosszabbítva 2048-ra valóban az amerikaiak 100 százaléka elhízott lesz, sőt a század végére már a 110 százalékuk lesz elhízott. Ez utóbbi adatból pedig jól látható a lineáris regresszió korlátja, hiszen a népesség 110 százaléka nem lehet elhízott. A valóságban tehát egy görbét fogunk látni, azaz az egyenes ellaposodik, és sosem érjük el a 100 százalékot. Bővebben itt foglalkoztunk a fenti problémával.
Az egyik legfontosabb szempont, hogy csak azokat az összefüggéseket fogadjuk el, melyek nagy számokon is megfigyelhetők. A clustering illusion legtöbb esete ezzel kizárható. Emellett gondoljunk józan paraszti ésszel, így az olyan ok-okozati összefüggések is kizárhatók, melyek bár nagy számokon is bizonyíthatók, de a valóságban belátható, hogy ilyen összefüggés nem létezik.
A bangladesi vajtermelés és a tőzsdei előrejelzés
Sullivan Timmermann a Data-snooping, technical trading rule performance, and the bootstrap tanulmány szerzője egy érdekes példát mutat be erre az esetre. Amikor a közgazdászok elkezdték keresni azokat a megbízható összefüggéseket, melyekkel az S&P500 index hozama megjósolható, akkor az egyik legjobban korreláló adat a bangladesi vajtermelés volt. Józan paraszti ésszel belátható, hogy a bangladesi vajtermelésnek semmi köze az S&P500 indexhez, azonban összetett, bonyolult, nem átlátható adatok esetében az emberek nem képesek ilyen jellegű elvonatkoztatásokat végezni, így elfogadjuk, hogy a kimutatott összefüggések között kapcsolat van, holott a valóságban csak a véletlen műve, ahogy a fenti példában is.
Az alábbi oldalon több statisztikailag szignifikáns összefüggést ismerhetsz meg, melyekről könnyedén belátható, hogy semmi közük egymáshoz, és csak a véletlen műve. Hogy lehetséges az, hogy statisztikailag szignifikáns vizsgálatok is fals eredményt hoznak. A válasz egyszerű, hiszen ha sok ezer kutatást végeznek el a világon, és a kutatások megbízhatósága 95%, vagy 99%-os, akkor az esetek 1-5% még nagyszámú estet jelent. Az alábbi grafikonon azt láthatjuk, hogy az Egyesült Államokban a tudományra, űrkutatásra, technológiára költött összegek és az öngyilkosságok száma között igen szoros (0,99) korreláció figyelhető meg. A valóságban a két adatnak semmi köze egymáshoz.

forrás: tylervigen.com
A medencébe fulladó emberek száma és Nicolas Cage filmszerepei között is közepesen magas (R =0,66) korreláció figyelhető meg.

forrás: tylervigen.com
Utolsó példaként álljon itt a margarin egy főre jutó fogyasztása és a válások aránya közötti erős korreláció (0,99).

forrás: tylervigen.com
Összegezve a fentiket a clustering illusion torzítását úgy kerülhetjük el a döntéseink során, ha olyan összefüggéseket veszünk figyelembe, melyek magas eseményszám mellett lettek kimutatva. Ez egyúttal azzal is jár, hogy a néhány eseten alapuló megfigyelésekből nem vonunk le következtetést. Illetve érdemes átgondolni az összefüggés ok-okozati viszonyát, hiszen számos esetben teljesen nyilvánvaló, hogy a két adat között nincs logikus összefüggés, így a kapott eredmények a sajátos adattartomány kiválasztásnak (data snooping bias) és a véletlennek a műve.
Ha kérdésed van a fentiekkel kapcsolatban, hozzá szeretnél szólni a témához, csatlakozz facebook csoportunkhoz ide kattintva!
Tanfolyamaink:
- Befektetési alapismeretek, stratégiák, részletek itt.
- Tőzsdei kereskedés magyar és külföldi piacokon, részletek itt.
- Rövid távú, daytrade kereskedés devizákkal, részvényekkel, részletek itt.
- Bitcoin és kriptoeszközök képzés, részletek itt.