Cikkünkben az R2, a magyarázóerő értelmezésével, gyakorlati használatával foglalkozunk. A tárgyalt ismeretek elsősorban azoknak a befektetőknek, tőzsdei kereskedőknek lesznek fontosak, akik döntéseiket különböző múltbeli, megbízható összefüggésekre alapozzák. A fentiek tekintetében megbeszéljük, mit jelent a lineáris regresszió, hogyan lehet a kapcsolatot kimutatni két összefüggés között. A tőzsde nyelvére lefordítva ez azt jelenti, hogy egyes tényezők képesek-e előre jelzeni a jövőbeni hozamot. Témáink:
- Hogyan zajlik a gyakorlatban az összefüggések kimutatása?
- Korrelációs együttható a befektetések területéről
- Mennyire bízhatunk meg a lineáris regresszióban?
Hogyan zajlik a gyakorlatban az összefüggések kimutatása?
Itt az oldalon és a tanfolyamunkon is nagyon sok ismert, a múltban megbízhatónak bizonyuló tőzsdei összefüggéssel foglalkoztunk. Vélhetően a tőzsdei kereskedők, befektetők széles köre találkozik az ismertebbekkel, például a value-tényezővel, momentum-hatással, size-effektussal, a CAPE-mutatóval és a sort hosszasan sorolhatnám, hiszen mára már száznál is több ilyen tőzsdei összefüggést ismerünk. Ezeknek a vizsgálatoknak a jelentős részében két adat között keressük a kapcsolatot. Ezek a vizsgálatok egyszerű lineáris regresszióval történnek.
A lineáris regresszióra nagyon jó példa a CAPE-mutató (magyarázat a mutatóhoz itt), melynél azt vizsgáljuk meg, hogy a mutató értéke és a jövőbeni részvénypiaci hozam között van-e bármiféle kapcsolat. Ha ezt a vizsgálatot el szeretnénk végezni, akkor ehhez két dologra van szükségünk. Az egyik a CAPE mutató értéke minden egyes évben az adott tőzsde vonatkozásában, a másik pedig a következő évi hozam a tőzsdén. Ha ezeket az adatok felvisszük egy táblázatba az egyik oszlopba a CAPE a másik oszlopban a jövő évi hozamot, akkor egy egyszerű grafikonon ábrázolhatjuk az összes esetet, ahogy ez az alábbi képen is látható (Shiller professzor kutatási anyagából másoltam ki a CAPE grafikonját).

forrás: Robert J. Shiller
A fenti képen minden egyes pont a CAPE mutató értékét és a következő évi tőzsdei hozamot mutatja. Ha ránézünk erre a ponthalmazra, látható, hogy az adatok tulajdonképpen véletlenszerűen szóródnak, azaz magas CAPE (túlárazott, drága részvénypiac) esetén is vannak magas jövő évi, és alacsony jövő évi hozamok. Ugyanígy alacsony CAPE (olcsó részvénypiac) esetében is vannak magas és alacsony jövőbeni hozamok. Már ránézésre megállapítható, hogy a CAPE és a jövő évi hozam között nincs szoros összefüggés. Ha viszont pontosak akarunk lenni, akkor a lineáris regresszió segítségével a pontokra illeszkedő egyenest veszünk fel. Ezt például excel táblázatkezelőben a Lin.Ill függvénnyel oldhatjuk meg.
A fenti grafikon látható egyenesből több dolog is következik. Általános összefüggést mutathatunk ki, illetve az egyenes meghosszabbításával jövőbeni előrejelzéseket tehetünk. Ilyenkor azonban az a kérdés, hogy ez az egyenes mennyire pontosan jelezte előre a múltban az eseményeket, azaz menyire pontosan illeszkedik az egyes a pontokra. A fenti kép alapján belátható, hogy semennyire, azaz a lineáris regresszióval felvett egyenes és a múltbeli adatok között nagy a szórás. Emiatt a CAPE mutató nem jelzi előre a jövő évi tőzsdei hozamokat. A megbízhatósági tényező, más néven R2, azaz magyarázóerő azt mutatja tehát, hogy a lineáris regresszióval felrajzolt egyeneshez milyen közel esnek az adatok.
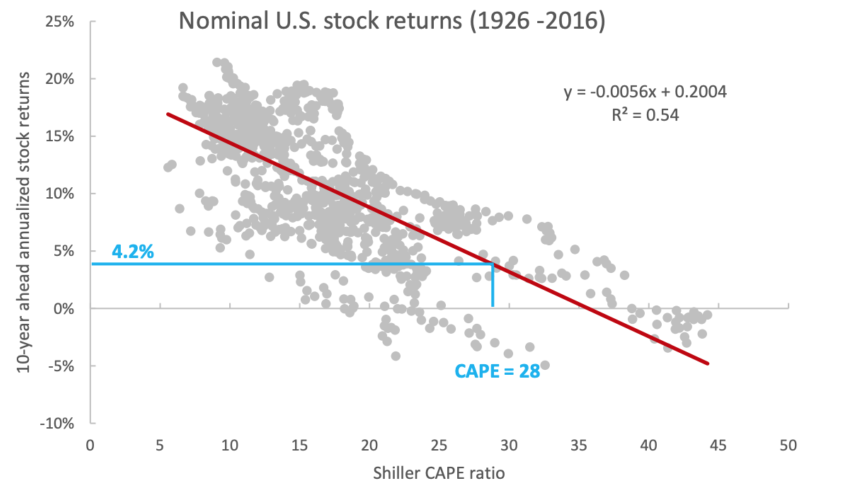
Az alábbi képen különböző hozam-előrejelző összefüggések megbízhatósága látható. Itt az R2 vizsgálata alapján a CAPE-mutató megbízhatósága a legjobb, de ebben az esetben a CAPE nem a következő évi, hanem a következő 10 év évesített hozamát jelzi előre.

Statisztikailag vizsgálva a 0,4-0,5 közötti R2 együttható alacsony korrelációnak tekinthető, így sajnos el kell azt fogadnunk, hogy nincs ennél jobb a tőzsdén. Az alábbi képen már a CAPE-mutató értéke és a 10 éves évesített hozam közötti összefüggés vizsgálható. Itt már a felvett pontok nem szóródnak annyira, és lényegesen közelebb vannak a lineáris regresszió módszerével meghúzott egyeneshez ( R2 = 0,52 ).
(grafikon forrása: https://alphaarchitect.com)
Rövidebb időtávon még szorosabb illeszkedést látunk. Itt már 0,9 az együttható értéke, de ez könnyen betudható annak, hogy alacsony az esetszám, így a véletlen eredménye.

forrás: advisorperspectives.com
Regressziós eljárások
A regressziós algoritmusok főként ott kerülnek felhasználásra, ahol számokkal kell dolgozni. Ilyen például a pénzügyek, gazdasági adatok és a mérnöki területek széles köre. A legismertebb regressziós eljárások:
- Linear Regression
- Nonlinear Regression
- Support Vector Machine Regression
- Gaussian Process Regression Regression Trees
A fentiek közül a lineáris regresszió példáján szemléltetjük az összefüggések kimutatásának egyszerűsített működését. A lineáris regresszió jelentősége, hogy x változóból próbáljuk megjósolni y változó értékét. Ezért a múltbeli, statikus adatokon kivizsgáljuk a kapcsolatot x és y változó között, megkeressük az adatsorra legjobban illeszkedő egyenest, majd az egyenest használjuk a jövőben arra, hogy x változásában y jövőbeni értékét előre jelezzük. Képzeljünk el egy olyan döntéstámogatási rendszert, mely az adott ország foglalkoztatottságának változásával próbálja megjósolni az adott ország tőzsdéjének öt éves évesített hozamát. Ebben az esetben feltételezzük, hogy kapcsolat van a foglalkoztatottság bővülés és az ország tőzsdei társaságainak teljesítménye, részvényeinek hozama között. A kitalált példánkban tehát a foglalkoztatottság (x) és a következő 5 év évesített hozama (y) közötti kapcsolatot keressük a múltbeli adatokon. Az alábbi grafikonon látható a MatLab alatt elkészített lineáris regresszió eredménye (az adatok, melyeket betápláltam, kitaláltak).

A grafikonon a kék körök mutatják az összes múltbeli esetet, a piros vonal az esetekre legjobban illeszkedő egyenest. A módszer további lépése a megbízhatóság, a magyarázóerő kiszámítása lenne, de itt ebben az esetben szemmel is látható, hogy az illesztett egyenes közelében vannak a pontok, azaz magas R2, magas megbízhatóságú összefüggést találtunk a példánkban. Az alábbi adatok meg is erősítik a szemrevételezést, azaz 90,6% a megbízhatóság. Természetesen az adatokból jól látszik, hogy nagyon kevés esetet vizsgáltunk meg (19 megfigyelés), amely miatt a vizsgálat nem statisztikailag szignifikáns (lásd pValue nagyobb, mint 0,05).

Tegyük fel, hogy a vizsgálatunk 19 megfigyelés helyett több ezer megfigyelésen alapul és statisztikailag szignifikáns lett az eredmény. Ebben az esetben a jövőbeni előrejzések során x ismert, és y-t az egyenes segítségével az y értéktengelyre levetítve olvassuk le. Például a foglalkoztatottság az előző évben 4 százalékot nőtt (x = 0,04), akkor az egyenest levetítve az y tengelyre 0,086, azaz 8,6 százalékot kapunk. Tehát az algoritmus 8,6 százalékos évesített hozamot jelez előre a következő 5 évre a részvénypiacon. Természetesen a lineáris regresszió a legegyszerűbb és sokszor nem pontos módja az előrejelzésnek. A fentiek tehát csak szemléltetési célt szolgálnak, hogy lássuk a pénzügyi összefüggések vizsgálata mögött milyen statisztikai módszerek húzódnak meg.
Mennyire bízhatunk meg a lineáris regresszióban?
Bár a lineáris regresszió egy hasznos eszköz, azonban a kimutatott összefüggések megbízhatóságát a jövőre nézve csak óvatosan szabad kiterjeszteni. Egyrészt előfordulhat az, hogy rövid időszakon vizsgáljuk a kapcsolatot, így a kapott eredmény csak a véletlennek köszönhető. Másrészt akkor is legyünk nagyon óvatosak, ha az összefüggés csak a múltbeli, in sample adatokon lett kimutatva. Erről a helyzetről beszéltem már a data snooping bias probléma tárgyalásakor. Megfigyelhető az a tendencia ugyanis, hogy az in sample adatokon kimutatott összefüggések megbízhatósága romlik, ha out of sample adatokon vizsgáljuk. Ez tehát azt jelenti, hogy kimutattunk egy összefüggést egy adatsoron, de ez az összefüggés más adatsoron, és így a jövőben sem lesz annyira megbízható. Erre mindenképpen figyeljünk oda. A harmadik problémát pedig maga a linearitás jelenti. A korrelációs együttható (R) nulla közeli értéke azt jelzi, hogy a két adat között nincs összefüggés. Ez azonban egész pontosan azt jelzi, hogy nincs lineáris kapcsolat, de másféle kapcsolat lehetséges. Ráadásul a gazdasági adatokban gyakran jellemző, hogy nem lineáris egyenesként írható le az összefüggés. Példaként az állami adóbevételek esetét gondoljuk át. Ha az állam emeli az adókulcsokat, akkor az adóbevételek növekednek. Itt tehát a két adat, az adókulcs mértéke és az adóbevételek között pozitív kapcsolat mutatható be.

Mi történik akkor, ha az állam az adókulcsokat 100%-ra emeli? A lineáris regresszió alapján azt gondolnánk, hogy így maximalizálhatná az adóbevételét az állam, holott a valóságban ebben a pontban nulla lenne az adóbevétele az államnak, mivel az emberek nem fizetnék be. Az adókulcs mértéke és az adóbevétel között tehát sokkal inkább egy az alábbi képen látható kapcsolat van.

A gazdasági életben és az élet más területén különböző összefüggések között nem feltétlenül van lineáris kapcsolat. Egy másik példaként egy 2008-as kutatást említenék meg, mely az amerikai nemzeti egészségügyi és táplálkozási vizsgálati program alapján kiszámolta, hogy 2048-ra az összes amerikai állampolgár túlsúlyos lesz. Ha ugyanis megvizsgáljuk az 1970-es éveket, akkor az amerikaiak 50% volt elhízott, a 90-es években már a 60 százalékuk, és 2018-ban már a 75 százalékuk. Ha ezt az összefüggést lineáris regresszióval vizsgáljuk, akkor az egyenest meghosszabbítva 2048-ra valóban az amerikaiak 100%-a elhízott lesz, sőt a század végére már a 110 százalékuk lesz elhízott. Ez utóbbi adatból pedig jól látható a lineáris regresszió korlátja, hiszen a népesség 110 százaléka nem lehet elhízott. A valóságban tehát egy görbét fogunk látni, azaz az egyenes ellaposodik, és sosem érjük el a 100 százalékot.
Ha kérdésed van a fentiekkel kapcsolatban, hozzá szeretnél szólni a témához, csatlakozz facebook csoportunkhoz ide kattintva!
Tanfolyamaink:
- Befektetési alapismeretek, stratégiák, részletek itt.
- Tőzsdei kereskedés magyar és külföldi piacokon, részletek itt.
- Rövid távú, daytrade kereskedés devizákkal, részvényekkel, részletek itt.
- Bitcoin és kriptoeszközök képzés, részletek itt.